
Tips for Dealing With Emergences
Using an ⛑️ EmergencyKit

When I was at Product Hunt, emergencies were very rare.
Between January 2019 (when I started counting) and March 2023 (when I left Product Hunt to co-found Angry Building), there were only 25 recorded emergencies. This means there was less than one emergency per month. Some of those emergencies were not user-facing.
We also had a very stable team. Our team was fully distributed between America, Europe, and Asia, so we had 24-hour coverage, and there was always an experienced engineer online.
Because of this, in my 8 years there, we didn't have an on-call process.
However, in early 2021, after we had grown the team, we experienced a few nasty outages in a row. During these, the core team members were unavailable, leaving relatively new and unprepared team members to deal with the incidents.
Due to this, I decided to tighten our ad-hoc process.
Nevertheless, I did not introduce an on-call role. Instead, I made dealing with incoming emergencies easier for everyone on the team.
The process of dealing with an emergency has 3 components. I have a similar process at Angry Building;
In this post, I'm going to walk through those components.

1) Detect emergencies
It is important to have a central place where all detection goes. I like to use Slack for this.
“feedback”—this is where all the rest of the company posts feedback exclusively for emergencies. This is when someone notices an issue. You want this to be THE LAST place you find out about emergencies.
“auto-engineering-sentry” - I like to use Sentry for exception tracking. This channel tracks every new exception. Usually, those are the first signs something is breaking. Both Product Hunt and Angry Building have very low numbers of unhandled exceptions.
“auto-engineering-alerts” - a catch-up channel receiving messages from services like PagerDuty (or betterstack.com), AWS CloudWatch, etc. Monitoring tools often have a way to alert you in Slack. I always have this channel on notification.

(example of alert from "auto-engineering-alerts")
💡 Tip about Slack channel naming
I like to follow the `prefix` naming scheme with Slack channels - "[type]-[team]-[name]".
I use the `auto` type for channels that receive messages from external systems.
The key is to ensure all channels maintain low noise ratios, especially the "auto-engineering-alerts" ones. It should be an event when something is posted there.
If you haven't found out about an outage from an automated tool, one of the first action items in your Postmortems should be - "update your monitoring to detect outages" (more on Postmortems later in this post)
2) Deal with emergencies
Here, we can use two tools "the engineering-emergency" Slack channel and the ⛑️ "Emergency Kit" documents
The Slack channel is where everyone gathers during an emergency; all communication is done there.
The benefits of this are:
Coordinating people - you don't want one person reverting a deploy while another attempts to deploy a quick-fix.
Makes writing postmortem about the incident easier because the whole history is there
There is a history of previous emergencies that can used as inspiration
The whole company sees that action is being taken and doesn't overload engineers' DMs.
For bigger incidents, the support team is in the loop so that they can communicate with our users about the incident
The Slack channel also has a link to the "Emergency Kit."

💡 Tip about Slack channels
One of my favorite unutilized Slack features is that you can add links to channels. It is especially useful for "project-" channels where you can link to project management tools, documents, metrics, etc.
⛑️ The Emergency Kit
It is a tutorial document and links a bag of information on what to do during an emergency.
It has the following parts.
A video walkthrough of how to diagnose issues - should be quick (2- 3 minutes) and straight to the point. This is very useful for first-time responders.
Tools - links to various dashboards and tools used to manage the application.
Process - quickly illustrated with diagrams (see example).
Tips & Tricks
Common Issues and Solutions.
How-tos - after tools, this is the area I use the most.
Here a gist with my template for the Emergency Kit 👉 ⛑️ Emergency Kit
You will notice the example document uses a lot of links and <details> HTML tags. The document should be a starting point and hub that is usable for novice and experienced responders.
I even knew all the systems by heart; I'll still use the document for the links and to copy/paste commands from how-tos.
The best way to handle issues is to start your exception tracker and then go to the database, application servers, and CDN.
If the issue isn't immediately obvious, I always follow those steps.
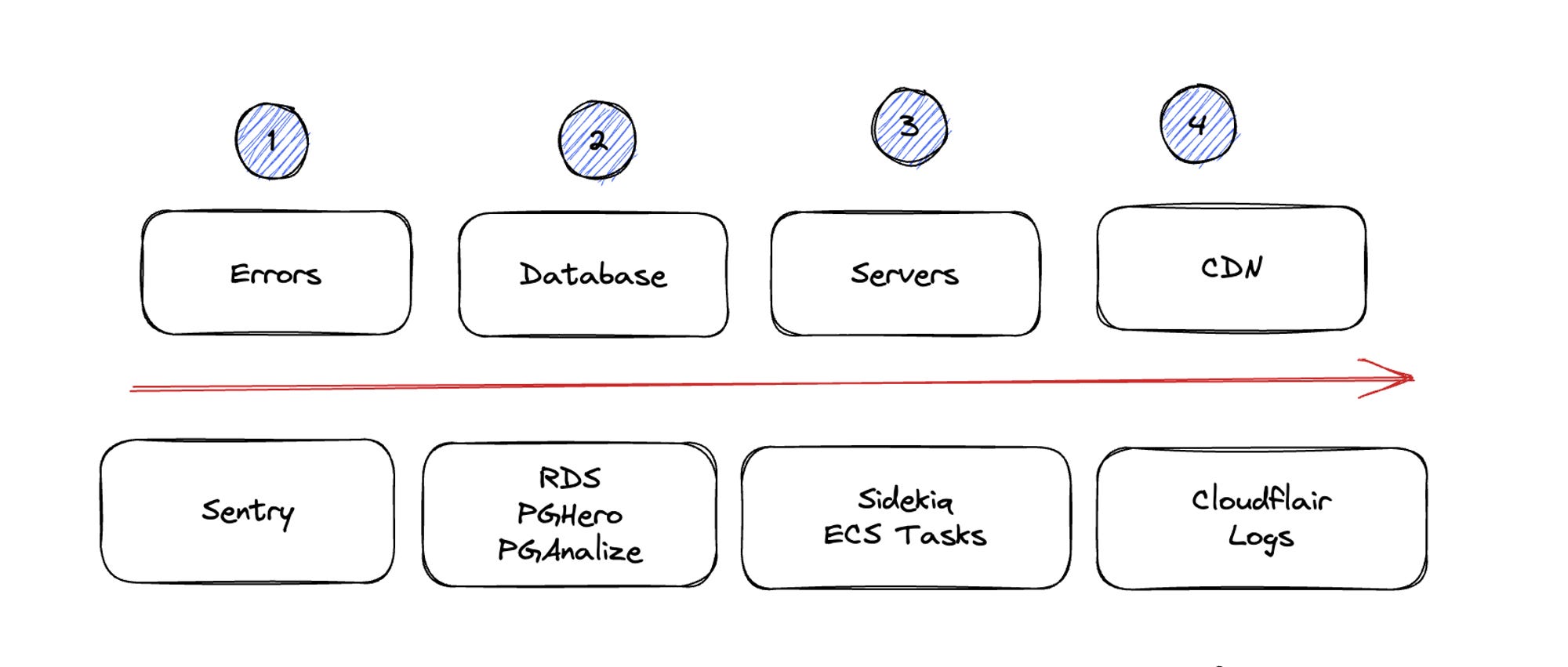
The usual issues I have encountered throughout my career are
Changes are not appearing after deploy
This happens if you have rolling deployments and the new version of the application can't boot. Often, exception tracking doesn't catch this, and you need to monitor one level below. If you use AWS, you can have Cloudwatch alerts for this.
Site is very slow (more than usual)
The corporate here often is the database. Usually, this is a symptom of something happening - traffic spike, expensive query, etc.
Another option might be to use more servers/containers to handle the load.
Check the status pages of the cloud provider (if you use a cloud provider). Once, we had an issue due to an AWS networking outage in our region.
There are a lot of 500s
Check your exception tracker; it will tell you what is failing
If there isn't anything there, the corporate is between services
Some evergreen tips for handling issues include:
Revert deploys till the last working deploy
Beware if there were database changes
When services depend on each other, like frontend JS app and backend API API, revert together
Check all recent code changes
focus first on the database, updated dependencies or infrastructure changes
look a couple days to a week back,
once, we had a nasty memory leak deployed a week ago
it was slowly creeping into our RAM
We saw it when we looked month data back on our RAM initialization
When browsing, monitoring data
Expand to 48 hour period and look for spikes in charts
Watch for response time, CPU, Memory
Isolate the issue to the lowest point in the tech stack
Have a way to do hotfixes deploys and bypass bureaucracy like every change should have a code review
You should have a way even to deploy without full CI tests suit pass, to build a docker image and push.
This should only be used in emergencies and should be restricted otherwise. You can have a restriction in GitHub to push to the main directly, but in an emergency, the org admin should be able to allow those deploys temporarily.
Things that should be included in the "how-to" area and known by everyone is
How to restart services
How to revert deploy
How to change the number of servers/containers/tasks/pods, etc
How to quickly deploy hotfix
Throughout my career, these are the common issues I have observed.
3) Improve system after emergency
After the emergency is handled, one of the engineers is assigned to write a blameless postmortem.
Here is a gist of the postmortem template I use 👉 link.
It is very useful to keep a database of all postmortems in a tool like Notion.
Two interesting tips we do with postmortems is
1. There are explicit action points to improve the emergency kit
2. We do a system walkthrough with the whole engineering team to review the steps taken so everyone is prepared for the next emergency.
We started having a video of the walkthrough, but no one was watching it, so it was better to do it on call. 🧐
I used the postmortem to improve documentation, monitoring, and system residency.
If you have any questions or comments, you can ping me on Threads, LinkedIn, Mastodon, Twitter or just leave a comment below 📭